10.01.2024По настоящее время
Lamoda
Как мы усовершенствовали обработку фотографий для интернет‑магазина Lamoda с помощью ML
Старт работы: изображения обуви
Новый объект обработки: сумки
Первые результаты
Рефакторинг и отказ от оболочки интерфейса
10.01.2024По настоящее время
Lamoda
Как мы усовершенствовали обработку фотографий для интернет‑магазина Lamoda с помощью ML
Технологии
Backend
Python
OpenCV
FastAPI
Pytorch
Tensorboard
Tensorflow
Награды
Заказчик
Lamoda — один из крупнейших интернет‑магазинов в России и СНГ, который специализируется на торговле одеждой и обувью.
Задача
Разработать ML‑решение, которое позволит снять с сотрудников рутинные задачи по ретуши фотографий — расположение объекта в кадре, коррекцию цвета фона и другие.
Старт работы: изображения обуви
Новый объект обработки: сумки
Первые результаты
Рефакторинг и отказ от оболочки интерфейса
Проблема
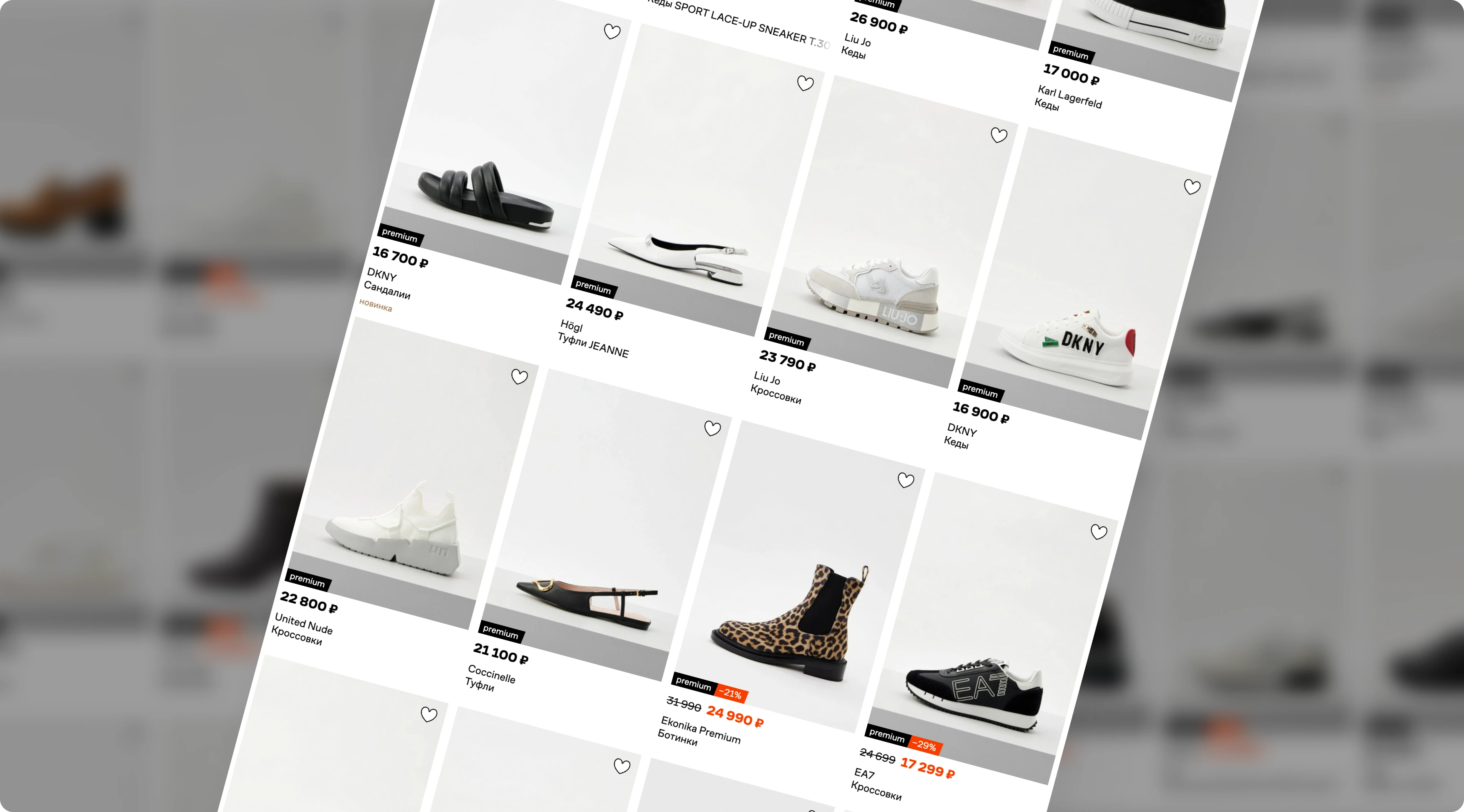
Одна из отличительных особенностей Lamoda — качественные фотографии в карточках, на которых можно детально рассмотреть каждый товар. Съемки происходят в фотостудии полного цикла. Через руки отдела ретуши проходит огромное количество изображений, из которых нужно отобрать самые качественные, расположить объект в кадрах под правильными углами, откорректировать фон. С помощью качественных фотоматериалов можно показать товар со всех сторон, подчеркнуть его достоинства для клиента.
Но если автоматизировать часть процессов обработки фото, можно существенно ускорить создание карточек и добавление товаров в интернет‑магазин. Например, в каждой карточке обуви представлено несколько фотографий, представляющих ее с разных ракурсов на светлом фоне. Для этих изображений есть стандарты: объект должен быть расположен в центре кадра, повернут под определенными углами. И вместо людей «подогнать» фото к нужному виду может нейросеть — это быстрее, чем ретушь вручную. Но есть сложности: углы поворота для нужных ракурсов не определены четко, есть только образцы изображений, где объекты расположены правильно или неправильно. Фотографы при съемке опираются на свои опыт и насмотренность, но снимки все равно необходимо обрабатывать и исправлять. С такой задачей к нам обратились представители Lamoda.
Решение
Для карточек в каталоге Lamoda важна ориентация объекта в кадре — он всегда должен быть расположен в центре, на фоне с градацией светлых оттенков, иметь определенную тень. Поэтому для решения задачи заказчика мы использовали ансамбль из двух нейронных сетей, которые определяют, что за снимок загружен:
Первая осуществляет дихотомическую сегментацию изображений. В результате изображение разделяется на сегменты или области, которые считаются однородными по некоторым критериям, например, по цвету, текстуре или интенсивности. «Дихотомический» означает «разделяющийся на две части», так что этот метод сегментации часто включает рекурсивное разделение изображения на более мелкие области до тех пор, пока не будут выполнены определенные условия однородности.
Вторая нейронная сеть, Deep‑OAD — это модель глубокого обучения, которая определяет угол ориентации естественного изображения.
Также мы использовали набор морфологических операций библиотеки OpenCV для обработки разных ракурсов объекта — в профиль, сверху, и для поворота в пространстве. Эти операции можно сравнить с последовательной обработкой изображения в Photoshop с помощью кистей и фильтров, но делается это не в интерфейсе редактора, а с помощью кода.

Определение контура обуви
Создание маски
Замена фона
Настройка контраста и яркости
Оптимизация освещения и теней на фоне
Вид объекта в профиль

Анализ альфа‑канала
Исправление наклона
Обрезка и масштабирование
Вид объекта сверху
Обработка поворота обуви

Предсказание угла поворота
Удаление фона
Центрирование
Синергия с заказчиком
Одно из условий успеха проекта — качественное взаимодействие с заказчиком. При работе над ML‑сервисом для Lamoda в чатах с клиентом кипела продуктивная совместная работа:
- мы проводили совместные исследования, обсуждали результаты и пути для развития;
- заказчик показывал множество референсов, чтобы улучшить работу сервиса.
Также мы получали тёплый фидбек, поддержку, шутили и смеялись.
Результат

Мы разработали решение, которое ускоряет процесс обработки фото, снимает с сотрудников однотипные, но требующие много времени задачи. Обработку изображения сервис осуществляет за 5–15 секунд, в зависимости от мощности процессора. Человеку на это нужно минимум несколько минут.
Продолжаем работу
Проект растёт: мы добавляем поддержку новых типов объектов и расширяем сценарии обработки. Тот же пайплайн, который мы отладили на обуви, теперь применяется и к другим категориям товаров.
Мы продолжаем обучать модели на новых данных, анализируем результаты и дорабатываем решения совместно с командой клиента. Так сервис эволюционирует вместе с бизнес‑задачами Lamoda.