Разработка ИИ-решения для поиска похожих изображений
04.04.202007.07.2020
Рассказываем, как разработали ML‑решение для поиска похожих изображений
Технологии
Python
Технологии машинного обучения всё больше расширяют набор инструментов, доступных бизнесу. Они помогают автоматизировать процессы, выполнить сложные задачи, которые не под силу человеку. Так, мы разработали универсальное решение, которое может помочь компаниям из разных сфер: нейросеть для поиска похожих изображений. Рассказываем, как и зачем мы это сделали.
Как появилась идея
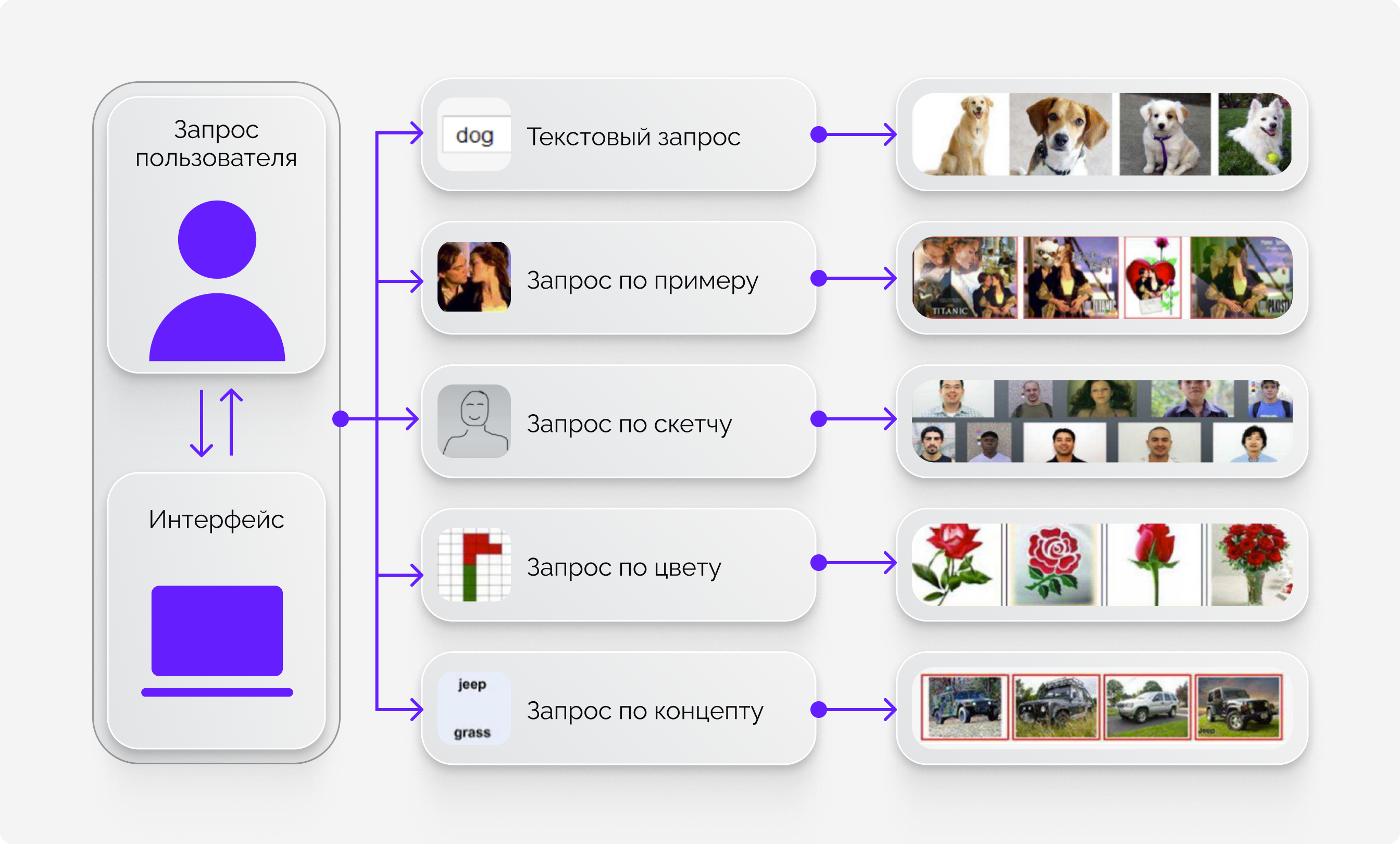
Изначально мы хотели сделать решение, полезное для e‑commerce: программу, которая сможет анализировать изображения и находить похожие. Например, во многих интернет‑магазинах есть поиск похожих товаров — пользователь может ввести запрос, и если ему не понравится результат, посмотреть товары, которые площадка позиционирует, как аналогичные. Но обычно этот механизм реализован на основе текстовых описаний товаров, которые далеко не всегда бывают точными и исчерпывающими. Мы разработали решение, которое анализирует непосредственно фотографию и находит визуально похожие предметы в каталоге. Благодаря ему подбор товаров становится более точным, а также пользователь может загрузить собственное изображение, которого нет в базе, нейросеть «считает» его и предложит подходящие позиции. Наша разработка может пригодиться не только владельцам маркетплейсов: любой проект, которому нужно быстро обрабатывать и сравнивать изображения. Например, эта технология может найти применение в медицине: анализировать рентгеновские снимки для поиска патологий. Сейчас она также используется на портале «Сибириана», созданном СФУ.
Как это работает
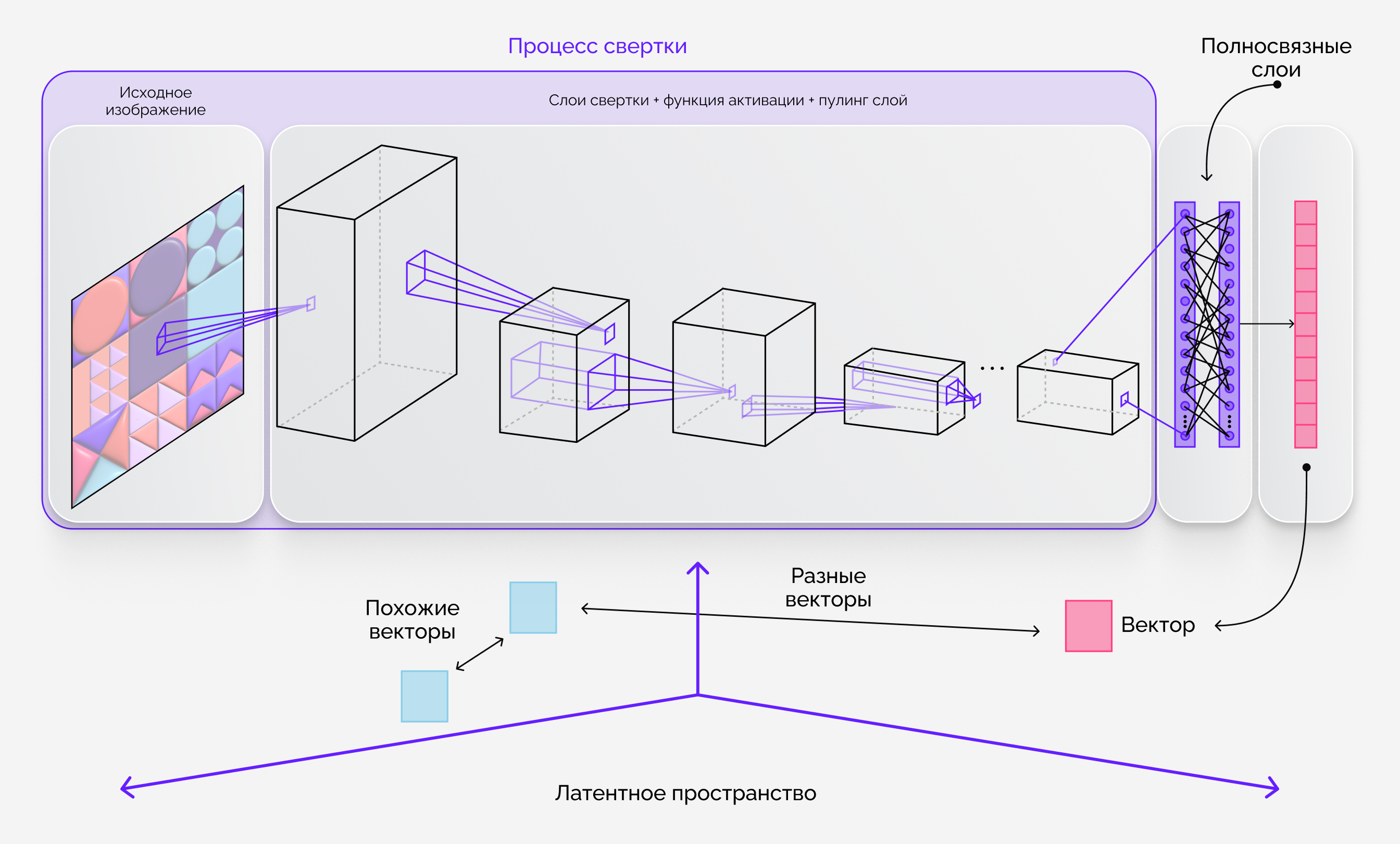
Мы разработали сверточную нейросеть: она «проходится» по изображениям, анализирует каждый пиксель, определяет его RGB‑код, обобщает информацию и потом на основе полученных данных делает вывод о том, насколько они схожи. После обработки картинка «превращается» в набор чисел, многомерный вектор. Чтобы определить, похожи ли изображения друг на друга, нейросеть сравнивает такие векторы. Все обработанные изображения хранятся в базе и могут использоваться для поиска. Для тренировки сети мы использовали метод обучения с учителем: один из самых точных и эффективных. Для этого программа получает большую базу изображений, объединенных в пары, и сравнивает их по заданным параметрам. Каждая пара в массиве подобрана человеком и определена, как похожие изображения. Чем более сложную задачу предстоит решать нейросети, тем больше должно быть таких пар: количество варьируется от 500 до 500 000 штук. Обучение на широких выборках делает программу чувствительнее и точнее. Для проверки после обучения проводится эксперимент: он похож на экзамен для нейросети. Учитель выдает несколько пар изображений и смотрит, насколько точно она определяет схожесть. Таких экспериментов может быть один, два и более — пока нейросеть не научится решать поставленную задачу с необходимой точностью. Поэтому сказать, что у нас есть готовый продукт, который достаточно просто «вставить» в любой проект, мы не можем: вместо этого предлагаем клиентам ИИ‑решение, которое обучаем отдельно для каждой задачи. Например, для маркетплейса нейросеть будет искать похожие платья или очки, а для внутреннего сервиса клиники — определять наличие новообразований на рентгеновском снимке. Для этих задач требуются разные базы изображений, разные эксперименты. Так, для поиска рака легких стоит точнее определить ложноположительные случаи, чем ложноотрицательные: лучше, если нейросеть «перебдит», чем пропустит начавшиеся изменения. Поэтому перед началом работы заказчик должен определить метрики: утвердить набор изображений для обучения и установить минимальную точность. Например, база из 65 тысяч товаров и точность от 90%. Так мы сможем натренировать нейросеть до нужного уровня, а клиент — получить объективные подтверждения эффективности программы. Глубокое погружение заказчика в проект увеличивает его успешность.
С какими проблемами мы столкнулись
Для создания нейросетей есть множество вариантов готовых базовых архитектур. Можно создать и с нуля — написать код для нескольких слоев нейронов и связей между ними, но так практически никто не делает. Мы перебрали много разных архитектур, в том числе — те, что обычно используются для подобных задач. Но ни одна из них не устроила нас полностью, и мы продолжили поиск. В итоге пришли к архитектуре визуальных трансформеров — ViT, которая позволила добиться более высокой точности по сравнению с классическими сверточными сетями. Она изначально создавалась для текстов, на ней работает в том числе ChatGPT, но сейчас ее иногда адаптируют для работы с изображениями, технологий компьютерного зрения. На больших выборках она может работать чуть медленнее, чем классическая архитектура, но выдавать значительно более высокую точность.
Результаты
Мы создали универсальное решение, которое может улучшить бизнес‑процессы в разных сферах — от интернет‑продаж до медицинской диагностики. Сейчас оно уже успешно используется несколькими крупными компаниями. Мы научились быстро и качественно адаптировать нейросеть к разным задачам бизнеса, поэтому готовы предлагать ее и другим нашим заказчикам. Визуальный поиск может ускорить работу компании, автоматизировать процессы, а также — улучшить клиентский сервис.